이 글은 개인의 학습을 목적으로 정리한 글입니다. 이점 참고하고 읽어주세요;)


메모리 = 주소를 통해 접근하는 매체
프로그램은 실행될 때 독자적인 메모리 주소를 가지게 됨. 이게 Logical address(virtual address)
메모리에 실제 올라가는 위치를 Physical address
물리적인 메모리는 0번부터 통으로 관리. 아랫부분에는 커널, 상위 부분에는 여러 프로그램들이 섞여서 존재
프로그램이 실제로 물리적인 메모리의 어떤 주소에 위치할지를 결정하는 것이 주소 바인딩
* Symbolic Address: 프로그래머가 숫자로 된 주소를 사용하지 않고 함수, 변수 등을 이용해서 프로그램을 만들고 또 메모리를 이용하는 것. 이게 컴파일이 되면 숫자 주소인 Logical address가 됨.
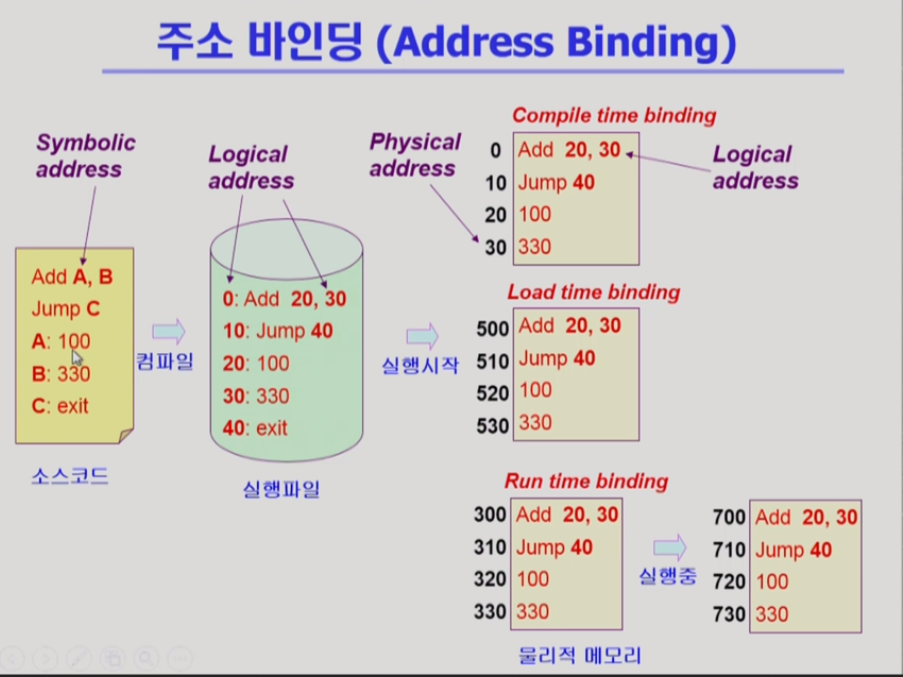
- 컴파일 타임 바인딩: 프로그램을 물리적 메모리 주소에 올릴 때에는 항상 논리적 메모리 주소 그대로 올림. 이게 컴파일 타임에 정해지기 때문에 비효율적. 때문에 논리적 주소가 곧 물리적 주소이기 때문에 컴파일 타임 바인딩에 의해 만들어진 코드를 Absolute code(절대 코드)라고 함. 물리적 메모리 주소를 변경하고 싶다면 컴파일 자체를 다시 해야 함.
- 로드 타임 바인딩: 프로그램이 시작돼서 메모리에 올라갈 때 물리적 주소가 결정됨. 컴파일 타임에 심볼릭 주소가 논리적 주소로 할당되고, 이 프로그램이 컴파일 이후 실행이 될 때 물리적 주소가 결정됨.
이 두 방식은 프로그램이 실행된 후에는 물리적 주소가 변하지 않음
- 런 타임 바인딩: 로드 타임과 마찬가지로 실행 시에 물리적 주소 할당. 하지만, 실행되는 도중에 물리적 메모리 주소가 이동될 수 있음. 때문에 CPU가 메모리 주소를 요청할 때 마다 바인딩을 체크해야 함(물리적 메모리 주소가 어디에 올라가 있는지). 이걸 위해서 하드웨어적인 지원이 필요함
CPU가 바라보는 주소는 Logical address. 물리적 주소를 바뀔 수 있지만, 로지컬 주소에 적힌 코드 즉, 컴파일된 내용은 변하지 않기 때문. 때문에 CPU는 논리적 주소로부터 물리적 주소를 읽어서 프로그램을 실행


주소변환을 실행시켜주는 하드웨어. 레지스터 두 개로 주소 변환이 이뤄짐.
Relocation register와 Limit register를 통해 주소를 변환.
실제로 프로그램이 위치한 물리적 주소의 시작위치에 논리적 주소의 위치를 더한 값에 위치하는 걸 CPU에 전달.
프로그램의 최대 크기(P1은 크기가 3000번지까지 존재)를 담고 있는 limit register를 통해 혹시 자신의 크기를 넘어서는 주소에 저장된 데이터를 가져오는 걸 방지.

logical address와 limit register를 먼저 비교. 만약 주소 범위가 limit을 벗어난다면 trap이 걸려서 CPU 제어권을 빼앗김
사용자 프로그램은 logical address만을 다룰 뿐이고, MMU가 logical address를 physical address로 변환해줌. CPU 역시 logical address를 받아서 작동.

1) Dynamic Loading

* Loading: 프로그램을 메모리에 올리는 것
Dynamic Loading: 해당 루틴이 필요할 때마다 메모리에 load. 프로그램은 대게 방어적으로 만들어지기 때문에 코드 중 많은 부분은 오류, 예외처리에 대한 부분들이고 자주 사용되는 부분들은 생각보다 적음.
현대 OS들 역시 프로그램을 실행시킬 때 프로그램 전체를 메모리에 올리지 않고 필요한 부분들만 메모리에 올리는 방법을 택하는데, 이는 Dynamic Loading이 아닌 Paging 기법이고, 운영체제에서 관리하는 부분. Dynamic Loading은 OS에서 관리하는 게 아니라 프로그래머가 관리하는 것
2) Overlays

Dynamic loading과 차이점? 사실상 같은 이야기. 메모리 크기가 작던 초창기 컴퓨터(하나의 프로그램을 메모리에 올리는 것도 힘겹던 시절) 환경에서 수작업으로 진행했던 프로그래밍.
3) Swapping


프로세스를 일시적으로 메모리에서 하드 디스크로 쫓아냄. 프로그램이 통째로 쫓겨남.
중기 스케줄러에 의해 일부 프로그램이 backing store로 쫓겨남.
컴파일과 로드 타임은 swap in에서 원래 위치로 찾아가야 하기 때문에 swapping의 효과를 십분 발휘하기 어려움.
방대한 양의 프로세스가 swap out과 swap in 되기 때문에 swap time 대부분이 데이터를 전송하는 transfer타임.(데이터를 찾고 접근하는 시간은 seek 타임).
4) Dynamic Linking

Linking: 컴파일된 파일들을 묶어서 하나의 실행 파일로 만드는 과정. 소스 파일을 직접 여러 개 만들어서 링킹 하기도 하고, 라이브러리도 링킹을 통해 실행 파일을 만들기도 함
Static linking: 라이브러리가 이미 실행파일의 코드에 포함( ex. printf 함수의 라이브러리 코드)
Dynamic linking: 라이브러리 코드가 실행 코드에 포함되지 않은 상태로 남아있다가, 프로그램을 실행했을 때 라이브러리를 호출했을 때 라이브러리를 찾음. printf 함수를 사용하는데, printf 라이브러리를 실행 파일에 포함시키지 않고 이걸 실행할 수 있는 라이브러리를 찾는 코드만 실행 파일에 저장. 때문에 printf 라이브러리를 찾는데 이미 메모리에 올라와있다면 그걸 공유해서 사용하면 됨. 이런 유형을 리눅스에서는 shared object, 윈도에서는 dll(dynamic linking library)

물리적 메모리의 낮은 부분에는 항상 OS 커널이 상주.
낮은 영역에는 사용자 프로세스들이 위치.
- Contiguous allocation: 프로그램 전체를 통째로 메모리에 올림
- Noncontiguous allocation: 프로그램을 구성하는 프로세스를 잘게 쪼개서 메모리의 여러 영역에 분산해서 올림. 현대 시스템에서 이걸 사용. 그 중 하나가 Paging 기법.


- 고정 분할: 사용자 프로그램이 들어갈 물리적 메모리를 미리 나눠놓음.
외부조각: 프로그램을 메모리에 올리고 싶은데, 메모리의 크기가 프로그램의 크기보다 작아서 사용하지 못하는 공간을 외부 조각이라고 함(External fragment).
내부 조각: 메모리가 프로그램보다 크기가 커서 남는 메모리 공간을 내부 조각(internal fragment).
- 가변 분할: 프로그램이 실행될 때 마다 차곡차곡 메모리에 프로그램을 올림. B가 종료되고 D가 실행되는데, B가 있던 공간은 D가 들어갈 수 없기 때문에 외부 조각으로 남음. 즉, 가변 분할 방식을 사용하더라도 중간중간 외부 조각이 발생하게 됨.
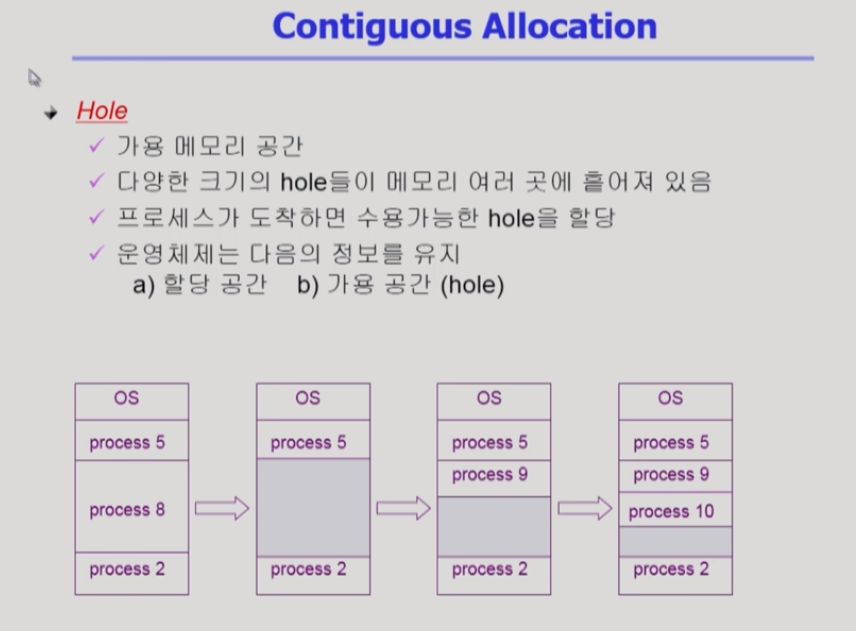

이러한 홀들이 산발적으로 발생하게 됨.
- Dynamic ~ :
1. First-fit: 제일 처음 발견되는 hole에 프로그램을 할당
2. Best-fit: hole을 다 살펴본 다음, 프로그램의 크기와 가장 잘 맞는 hole에 프로그램 할당
3. Worst-fit: 가장 큰 hole을 찾은 다음 프로그램 할당.

실행중인 메모리 영역을 밀어내기 때문에 쉽지 않은 작업. 여러 프로그램의 바인딩을 확인하는 등 비용이 많이 들고 복잡한 작업. 런 타임 바인딩이 꼭 지원이 되어야만 가능.

현대의 시스템에서 사용하는 방식은 Noncontiguous.
물리적 메로리는 page frame으로 나눠져 있기 때문에, 프로세스를 동일한 크기로 paging 해서 물리적 메모리에 올림. 이를 통해 홀들의 크기가 제각기 달라서 발생하는 문제들을 해결 가능.(동일한 크기의 frame으로 paging 되어있기 때문) 대신 주소 변환이 어려워짐.
Segmentation: 주소공간을 동일한 크기로 자르지 않고, 의미 있는 단위로 자름. 크게 코드, 데이터, 스택으로 나눔. 더 잘게 나누는 것도 가능. 크기가 균일하지는 않음. 때문에 dynamic linking에서 발생하는 문제도 발생.
'Information Technology > OS' 카테고리의 다른 글
| [운영체제] Memory management(3) (0) | 2020.02.29 |
|---|---|
| [운영체제] Memory management(2) (0) | 2020.02.26 |
| [운영체제] Deadlock (0) | 2020.02.17 |
| [운영체제] Process Synchronization(4) (0) | 2020.02.13 |
| [운영체제] Process Synchronization(3) (0) | 2020.02.10 |



